Product Recommendations in RedisGraph, Part 2: openCypher Query Basics
This post is part of a series on leveraging RedisGraph for product recommendations.
It’s a hot time for Redis! RedisConf 2020 is happening virtually and there are many interesting topics on Redis and RedisGraph. Check it out!
Back in Fall 2015 Emil Eifrem, CEO/co-founder of Neo4j, announced openCypher at GraphConnect in San Francisco. OpenCypher, inspired by Cypher, was Neo4j’s 3rd attempt at a graph query language. The growth and adoption of graph tech they experienced alongside other vendors began to expose and emphasize the need for a common query language against Graphs – someting similar to SQL for relational DBs. With Emil’s announcement openCypher was born. Here we’ll talk about how to use openCypher generally and in the context of the product recommendation proof of concept (POC) I’ve been building with RedisGraph.
This post is broken up into the following sections…
- A very brief overview of graphs
- Specifics of this e-Commerce-related graph generation POC
- Basics of querying
- Queries related to common questions of e-Commerce data
- Product recommendation queries
- What’s next
- Additional reading materials
Graph Basics
Graphs are, very simply put, structures composed of nodes and relationships, or edges. Relationships connect nodes and can be directed. There are also many different types of graphs. Redis Graph is a directed, labeled, multigraph where both nodes and relationships are typed – nodes with labels and edges with types. Nodes and edges can and often do contain properties like columns in a SQL-db or keys in a document store. Generally speaking, graphs excel at deriving information from the interconnectedness of data – as opposed to SQL or document systems where similar queries would require joining many tables or linking many collections.
Consider the following output from RedisInsight on a graph created from my commerce recommendation POC tooling (the process for generating it is outlined in this post):
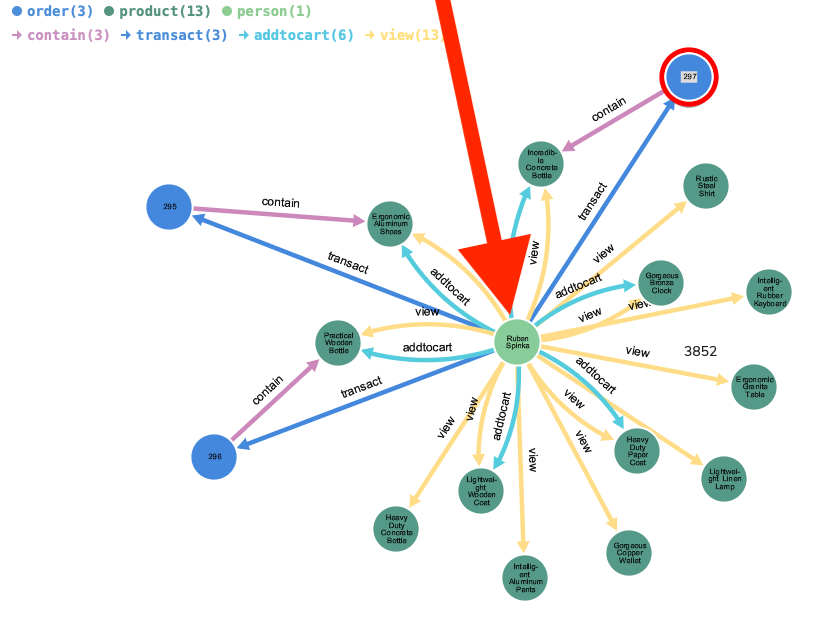
The centered, light green node with the giant red arrow pointing at it is a person-labeled node and is the center point
for this graph expansion. In total, there are three node “varieties” created in this POC:
person-labeled nodes (again, shown in light green)product-labeled nodes shown in dark greenorder-labeled nodes in dark blue
The edges in the system exist to represent the following actions or connections:
- When a
personviews aproduct– shown as yellow directed lines - When a
personadds a product to their cart – shown as cyan directed lines - When a
personplaces (transacts) anorderwhich contains a product – shown as blue directed lines
To keep the sample dataset as realistic as possible, addtocart edges are only created from a subset of the view edges
that exist between a person and product node.
All of the relationships in this POC and post are directed, which are denoted by the arrows in the graph visualization.
Graph Generation
The graph generation tooling runs through two phases to seed and populate the graph:
-
The creation of independent nodes occurs via
createstatements. Three node “varieties” are created:person,product, andorder. Technically the “variety” of a node is referred to as a label. We’ll step through distinct examples of each node - label creation. The following are the create statements used to insert these nodes into the graph.CREATE (:person { id: 4, name:"Javier Bashirian", age:94, address:"36186 Koelpin Isle, Lake Rashidahaven, OH 78740", memberSince:"2011-01-07T07:49:21.274235"})The
CREATEstatement takes a node enclosed by parenthesis with its label defined with a colon and the label ex:person. Properties for nodes are defined within the bounds of left and right curly brackets{ }. Each property must contain a string key separated by a colon and the value, which must equal one of the supported types. Multiple properties are separated by commas.In these examples
idis a property the application is setting on the node, which can be used for querying/matching, but is not the unique ID of the node in the graph itself – an important distinction. The internal ID of a node or relationship can be obtained via the Scalar functionid().In the following statement two nodes of the label
productare created with their various properties.CREATE (:product { id: 0, name:"Mediocre Granite Shirt", manufacturer:"Hoppe-Fahey",msrp:'812.68'} ), (:product { id: 3, name:"Awesome Iron Hat", manufacturer:"Willms, Mills and Wolf", msrp:'753.17'} ))Per the openCypher spec, nodes are supposed to support multiple labels and edges or relationships are supposed to support multiple types. As of this writing, RedisGraph does not support at least multiple node labels, but there is an issue tracking that enhancement.
Our final node type created in this POC is of label
order:CREATE (:order { id: 2, subTotal:1565.85, tax:176, shipping:208, total:1949.85} ) -
The next crucial component of this graph creation is the relationships/the edges – they do the connecting, the entire reason for having a graph in the first place.
Here the tooling is instructing the graph to execute a sort of conditional create where its first matching nodes of various types, then creating a relationship between those nodes.
MATCHis used to tell the graph to find the nodes, a path, relationships, etc…Consider the following statement:
MATCH (p:person), (o:order), (prd3:product), (prd0:product) WHERE p.id=4 AND o.id=2 AND prd3.id=3 AND prd0.id=0 CREATE (p)-[:transact]->(o), (o)-[:contain]->(prd3), (o)-[:contain]->(prd0)This query instructs the graph to match and find nodes with labels
person,order, andproduct. These look similar to the create statements before except the labels have a leading identifier prior to the colon and label declaration. These identifiers, termed an alias,p,o,prd3, andprd0are exclusive to the query. The aliases could be anything. However, the graph generation tooling uses sensible names for these aliases, though, which is whyprd3andprd0are used. These aliases in and of themselves do not restrict us to “product 3” and “product 0”. The restrictions to those product ids come in theWHEREsegment of the query:WHERE p.id=4 AND o.id=2 AND prd3.id=3 AND prd0.id=0…where alias
p, which is a node labelperson, with propertyidequal to4, etc…Only when this conditional is met do we create our edges, our relationships:
CREATE (p)-[:transact]->(o), (o)-[:contain]->(prd3), (o)-[:contain]->(prd0)The
CREATEstatement here is creating three edges of types:transactandcontain. Thecreatestatements are leveraging the same aliases we used for ourMATCHstatement, which now makes it a little more clear why they are explicitly namedp,o,prd3, andprd0.The prior
MATCHstatement associated ourperson-labeled node with the createdorder-labeled node and the order with theproduct-labeled nodes theordercontains. The next statement associates ourpersonnode withproductnodes they’ve viewed and added to their carts.MATCH (p:person), (prd1:product), (prd3:product), (prd2:product), (prd0:product), (prd4:product) WHERE p.id=4 AND prd1.id=1 AND prd3.id=3 AND prd2.id=2 AND prd0.id=0 AND prd4.id=4 CREATE (p)-[:view {time: '2018-07-18T15:54:21.274235'}]->(prd1), (p)-[:view {time: '2013-04-16T02:10:21.274235'}]->(prd3), (p)-[:view {time: '2012-10-22T15:51:21.274235'}]->(prd2), (p)-[:view {time: '2012-11-05T18:29:21.274235'}]->(prd0), (p)-[:view {time: '2017-09-02T15:22:21.274235'}]->(prd4), (p)-[:addtocart {time: '2013-04-19T02:01:21.274235'}]->(prd3), (p)-[:addtocart {time: '2012-11-07T14:43:21.274235'}]->(prd0)This example has a few more aliases, but primarily differs from the other in that a property is set on the edge, on the relationship. Note that the syntax for doing so is identical to the nodes.
(p)-[:addtocart {time: '2012-11-07T14:43:21.274235'}]->(prd0)Types and syntax are the same for relationships as for nodes.
Querying the Graph
Next we’ll zip through some examples of running queries and functions on the graph. Each example is broken into an easier to read version of the query and the execution of the query using the redis command line tooling.
-
Query the distinct labels in the graph. The following query will match any node, any match aliased with
n, returning distinct results from thelabels()function.match (n) return distinct labels(n)Executed:
127.0.0.1:6379> graph.query prodrec "match (n) return distinct labels(n)" 1) 1) "labels(n)" 2) 1) 1) "person" 2) 1) "product" 3) 1) "order" 3) 1) "Query internal execution time: 10.429400 milliseconds"An alternative approach to this specific query is calling the
db.labels()function. This is an optimized function and should be preferred for this type of query – note the difference in response time.Executed:
127.0.0.1:6379> graph.query prodrec "call db.labels()" 1) 1) "label" 2) 1) 1) "person" 2) 1) "product" 3) 1) "order" 3) 1) "Query internal execution time: 0.179300 milliseconds" -
Query the distinct edges or relationships in the graph. The following query will match any directed relationship, aliased with
e, between an un-aliased source and destination node of any label, returning distinct types from thetype()function.match ()-[e]->() return distinct type(e)Executed:
127.0.0.1:6379> graph.query prodrec "match ()-[e]->() return distinct type(e)" 1) 1) "type(e)" 2) 1) 1) "view" 2) 1) "addtocart" 3) 1) "transact" 4) 1) "contain" 3) 1) "Query internal execution time: 200.475200 milliseconds"An alternative approach to this specific query is calling the
db.relationshipTypes()function. Just like the other DB function call, this is also optimized and should be preferred for this type of query – note the difference in response time.127.0.0.1:6379> graph.query prodrec "call db.relationshipTypes()" 1) 1) "relationshipType" 2) 1) 1) "view" 2) 1) "transact" 3) 1) "contain" 4) 1) "addtocart" 3) 1) "Query internal execution time: 0.166000 milliseconds" -
Query the distinct labels in the graph and obtain their counts – similar to the aforementioned query in ex: #1, with an added
count.match (n) return distinct labels(n), count(n)Executed:
127.0.0.1:6379> graph.query prodrec "match (n) return distinct labels(n), count(n)" 1) 1) "labels(n)" 2) "count(n)" 2) 1) 1) "order" 2) (integer) 11663 2) 1) "person" 2) (integer) 5000 3) 1) "product" 2) (integer) 1000 3) 1) "Query internal execution time: 7.088800 milliseconds" -
Query the distinct edges (or relationships) in the graph – similar to the aforementioned query in ex: #2, with an added
countmatch ()-[e]->() return distinct type(e), count(e)Executed:
127.0.0.1:6379> graph.query prodrec "match ()-[e]->() return distinct type(e), count(e)" 1) 1) "type(e)" 2) "count(e)" 2) 1) 1) "addtocart" 2) (integer) 30995 2) 1) "contain" 2) (integer) 28250 3) 1) "transact" 2) (integer) 11663 4) 1) "view" 2) (integer) 119276 3) 1) "Query internal execution time: 177.944000 milliseconds" -
Obtain the id of a node. The following query will match a node of type
personwith the query aliaspand the conditional, property,id==3returning the actual ID of the node via theidfunction.match (p:person) where p.id=3 return id(p)Executed:
127.0.0.1:6379> graph.query prodrec "match (p:person) where p.id=3 return id(p)" 1) 1) "id(p)" 2) 1) 1) (integer) 3 3) 1) "Query internal execution time: 0.455100 milliseconds"In this case the id of the node and the nodes property
idare identical. The graph creation utility is multi-threaded, though, and not all nodes share that same trait. Ex:127.0.0.1:6379> graph.query prodrec "match (p:person) where p.id=493 return id(p)" 1) 1) "id(p)" 2) 1) 1) (integer) 497 3) 1) "Query internal execution time: 0.627600 milliseconds" -
Obtain the id of a node. In this query, match statement is identical to the prior one, but here we specify the required property match in the node itself rather than with a
whereclause.match (p:person {id: 3}) return id(p)Executed:
127.0.0.1:6379> graph.query prodrec "match (p:person {id: 3}) return id(p)" 1) 1) "id(p)" 2) 1) 1) (integer) 3 3) 1) "Query internal execution time: 0.389400 milliseconds" -
Obtain the id of a relationship or edge. This query is similar to aforementioned query in ex: #2; match any directed relationship, aliased with
e, between an un-aliased source and destination node of any label, returning the ID of the relationship via theidfunction.match ()-[e]->() return id(e) limit 1Executed:
127.0.0.1:6379> graph.query prodrec "match ()-[e]->() return id(e) limit 1" 1) 1) "id(e)" 2) 1) 1) (integer) 41 3) 1) "Query internal execution time: 0.418200 milliseconds"
e-Commerce Product-related Queries
-
Return the top 3 people (
idandnameproperties) who have created the most orders. This query will match a path where a node of labelpersonwith aliaspwith a directional edge of labeltransactto a node of labelorderwith aliaso. Theid,name, and count asordersare returned in descending order and limited to 3.match (p:person)-[:transact]->(o:order) return p.id, p.name, count(o) as orders order by orders desc limit 3Executed:
127.0.0.1:6379> graph.query prodrec "match (p:person)-[:transact]->(o:order) return p.id, p.name, count(o) as orders order by orders desc limit 3" 1) 1) "p.id" 2) "p.name" 3) "orders" 2) 1) 1) (integer) 1388 2) "Marion Mante" 3) (integer) 17 2) 1) (integer) 4977 2) "Birdie Oberbrunner" 3) (integer) 17 3) 1) (integer) 1871 2) "Towanda Funk" 3) (integer) 16 3) 1) "Query internal execution time: 55.890400 milliseconds" -
Return the top 3 most ordered products (
idandnameproperties). This query will match a path where a node of labelorderwith a directional edge of typecontainwith an aliascto a node of labelproductwith aliasp. Theid,name, and count ascountare returned and limited to 3.match (:order)-[c:contain]->(p:product) return p.id, p.name, count(c) as count order by count desc limit 3Executed:
127.0.0.1:6379> graph.query prodrec "match (:order)-[c:contain]->(p:product) return p.id, p.name, count(c) as count order by count desc limit 3" 1) 1) "p.id" 2) "p.name" 3) "count" 2) 1) 1) (integer) 592 2) "Rustic Paper Hat" 3) (integer) 44 2) 1) (integer) 203 2) "Sleek Silk Lamp" 3) (integer) 43 3) 1) (integer) 987 2) "Intelligent Steel Computer" 3) (integer) 43 3) 1) "Query internal execution time: 120.565500 milliseconds" -
Return the top 3 most viewed products (
idandnameproperties). This query will match a path where a node of labelpersonwith a directional edge of typeviewwith aliasvto a node of labelproductwith aliasp. Theid,name, and count ascountare returned and limited to 3.match (:person)-[v:view]->(p:product) return p.id, p.name, count(v) as count order by count desc limit 3Executed:
127.0.0.1:6379> graph.query prodrec "match (:person)-[v:view]->(p:product) return p.id, p.name, count(v) as count order by count desc limit 3" 1) 1) "p.id" 2) "p.name" 3) "count" 2) 1) 1) (integer) 189 2) "Aerodynamic Wool Wallet" 3) (integer) 151 2) 1) (integer) 39 2) "Incredible Silk Lamp" 3) (integer) 148 3) 1) (integer) 713 2) "Small Concrete Lamp" 3) (integer) 148 3) 1) "Query internal execution time: 160.342500 milliseconds" -
Return the 3 fewest purchased products (
idandnameproperties). This query will match a path where a node of labelorderwith a directional edge of typecontainwith aliascto a node of labelproductwith aliasp. Theid,name, and count ascountare returned in descending order and limited to 3.match (:order)-[c:contain]->(p:product) return p.id, p.name, count(c) as count order by count limit 3Executed:
127.0.0.1:6379> graph.query prodrec "match (:order)-[c:contain]->(p:product) return p.id, p.name, count(c) as count order by count limit 3" 1) 1) "p.id" 2) "p.name" 3) "count" 2) 1) 1) (integer) 763 2) "Small Bronze Computer" 3) (integer) 12 2) 1) (integer) 984 2) "Fantastic Plastic Gloves" 3) (integer) 13 3) 1) (integer) 266 2) "Durable Linen Clock" 3) (integer) 14 3) 1) "Query internal execution time: 125.494000 milliseconds" -
Return products not purchased. This query will match a path for every node of label
productwith aliaspwhere no node of labelorderwith directional edge typecontainpoints to saidproduct-labeled nodep. Return the count.match (p:product) where not (:order)-[:contain]->(p) return count(p)Executed:
127.0.0.1:6379> graph.query prodrec "match (p:product) where not (:order)-[:contain]->(p) return count(p)" 1) 1) "count(p)" 2) (empty array) 3) 1) "Query internal execution time: 357.291000 milliseconds"The default settings of the script mean that this particular query usually does not return results.
-
Queries can be strung together linearly using
withallowing for their individual execution and results handling. Consider the following example where we want the count ofview,addtocart, andcontain-typed edges along with aproduct-labled node’sname.match (prod:product {id: 393})<-[c:contain]-(:order) with prod, count(c) as orders match (prod)<-[atc:addtocart]-(:person) with prod, orders, count(atc) as addstocarts match (prod)<-[v:view]-(:person) with prod, orders, addstocarts, count(v) as views return prod.name, orders, addstocarts, viewsThe initial
product-labeled node aliased withprodis matched based off theidproperty set to393.Note the pattern of “match with”. Each
matchstatement runs like a pipeline, passing the parameters to the next.- In the first we create a path from
order-labeled nodes via thecontain-typed edge with an aliasc. The alias exists so we can count and pass the value along with theproduct-labeled node aliased asprod. - In the second we create a path from the passed
prodfrom aperson-labeled node via theaddtocart-typed edge with an aliasatc. Because we want the add to cart count and the order count we are passing out what we took in. - In the final “match with” we take the three inputs and create a path from the passed
prodfrom aperson-labeled node via theview-typed edge with an aliasv.
The final return statement returns the product name along with each value.
Executed:
127.0.0.1:6379> graph.query prodrec "MATCH (prod:product {id: 393})<-[c:contain]-(:order) WITH prod, count(c) as orders MATCH (prod)<-[atc:addtocart]-(:person) WITH prod, orders, count(atc) as addstocarts MATCH (prod)<-[v:view]-(:person) WITH prod, orders, addstocarts, count(v) as views return prod.name, orders, addstocarts, views" 1) 1) "prod.name" 2) "orders" 3) "addstocarts" 4) "views" 2) 1) 1) "Gorgeous Cotton Shoes" 2) (integer) 30 3) (integer) 33 4) (integer) 131 3) 1) "Query internal execution time: 5.319900 milliseconds" - In the first we create a path from
-
Merge statements ensure a path exists in the graph and allow you to take some action when “on match” or “on create” conditions are met. Take the following example where instead of computing the values from the last example each time, we wanted to periodically set them on the nodes themselves.
match (prod:product)<-[c:contain]-(:order) with prod, count(c) as orders match (prod)<-[atc:addtocart]-(:person) with prod, orders, count(atc) as addstocarts match (prod)<-[v:view]-(:person) with prod, orders, addstocarts, count(v) as views merge (prod) on match set prod.num_orders = orders, prod.num_adds_to_carts = addstocarts, prod.num_views = views return prod.id, orders, addstocarts, viewsThis query very similar to the first except for a few ways. The initial
matchstatement doesn’t single out a particular product. A merge statement exists on theprodalias for theproduct-labeled node that was “match with”-ed three times. On a match, the statement takes the passed values at establishes them on theproduct-labeled node itself. The values are returned along with the product id.Executed (with omitted nodes):
127.0.0.1:6379> graph.query prodrec "MATCH (prod:product)<-[c:contain]-(:order) WITH prod, count(c) as orders MATCH (prod)<-[atc:addtocart]-(:person) WITH prod, orders, count(atc) as addstocarts MATCH (prod)<-[v:view]-(:person) WITH prod, orders, addstocarts, count(v) as views merge (prod) ON MATCH SET prod.num_orders = orders, prod.num_adds_to_carts = addstocarts, prod.num_views = views return prod.id, orders, addstocarts, views" 1) 1) "prod.id" 2) "orders" 3) "addstocarts" 4) "views" 2) 1) 1) (integer) 0 2) (integer) 29 3) (integer) 33 4) (integer) 127 // omitted nodes // 406) 1) (integer) 393 2) (integer) 30 3) (integer) 33 4) (integer) 131 // omitted nodes // 1000) 1) (integer) 999 2) (integer) 27 3) (integer) 28 4) (integer) 126 3) 1) "Properties set: 3000" 2) "Query internal execution time: 263.394600 milliseconds"Here we query for the node via:
match (p:product) where p.id=333 return p… in RedisInsight to produce and show the results from the
merge.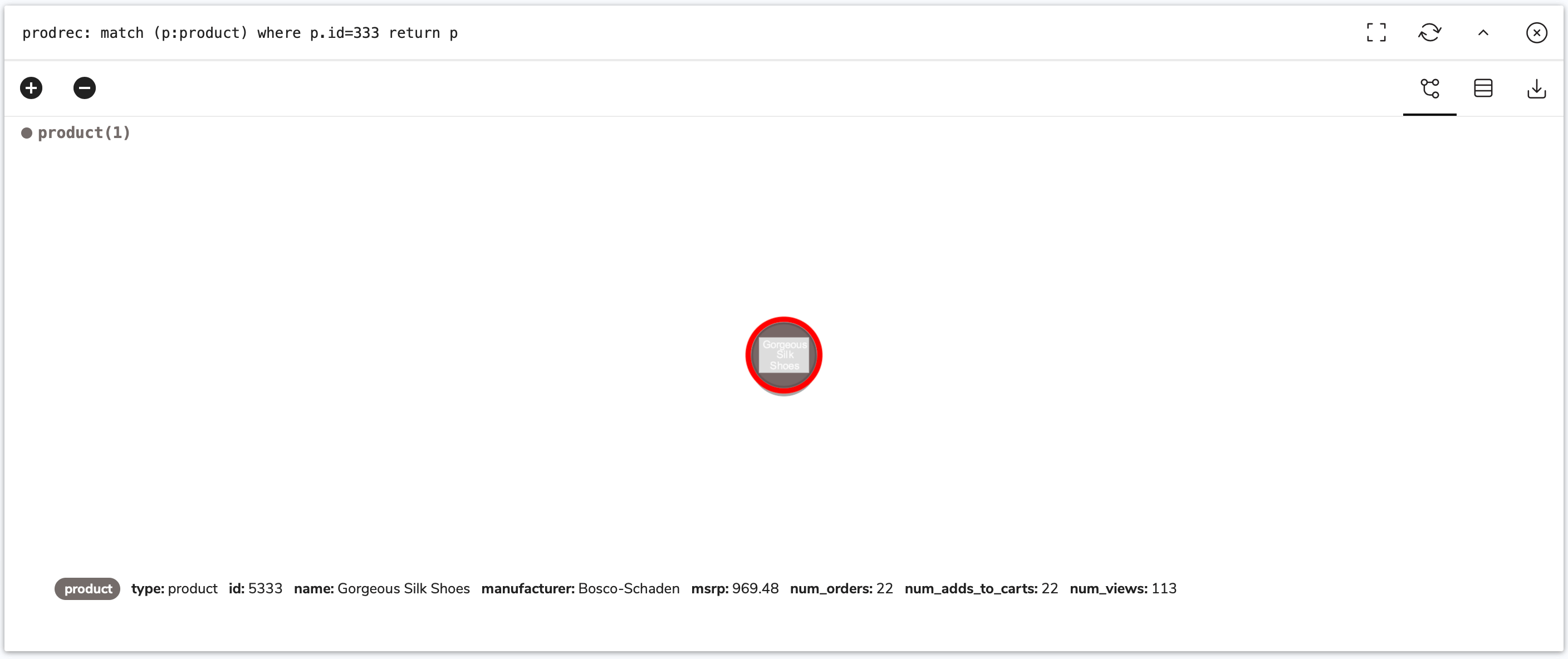
The next section will get into more powerful paths through the nodes and edges in the system and begin to show the power of openCypher and the graph.
Basic Product Recommendation Queries
There are a number of ways you could extract meaningful information about what to recommend to a user. These next few examples highlight a very crude
approach to recommendations where we want to show all the product nodes that share orders in common with the product nodes in the transacted
order nodes for a given person. In the first example the person targeted is identified by their id property 294.
-
Find products that are in orders that have common products placed by person id 294. Limit results to 1 (so this blog post isn’t terribly long).
match (p:person)-[:transact]->(:order)-[:contain]->(:product)<-[:contain]-(:order)-[:contain]->(prd:product) where p.id=294 return distinct prd limit 1This statement really shows the benefit of cypher over something like SQL, which would require many joins to accomplish the same query. Here we trace the path, telling the graph to match
people-labeled nodes, through theproduct-labeled nodes they’ve purchased to theproduct-labeled nodes of all orders that shared thatproductin common.This query only aliases the
personlabeled node at the startpand theproductlabeled node at the endprd. Given, though, thatponly exists so that can use it to filter based on its id in thewhereclause.Executed:
127.0.0.1:6379> graph.query prodrec "match (p:person)-[:transact]->(:order)-[:contain]->(:product)<-[:contain]-(:order)-[:contain]->(prd:product) where p.id=294 return distinct prd limit 1" 1) 1) "prd" 2) 1) 1) 1) 1) "id" 2) (integer) 5000 2) 1) "labels" 2) 1) "product" 3) 1) "properties" 2) 1) 1) "id" 2) (integer) 1 2) 1) "name" 2) "Gorgeous Plastic Wallet" 3) 1) "manufacturer" 2) "Terry and Sons" 4) 1) "msrp" 2) "42.46" 3) 1) "Query internal execution time: 1.889600 milliseconds"This could be re-written as:
match (p:person { id: 294 })-[:transact]->(:order)-[:contain]->(:product)<-[:contain]-(:order)-[:contain]->(prd:product) return distinct prdThis query returns the alias for
product,prd, itself and therefor we get all the details for that node. -
The following is a minor variation over the last example where we go a step further to remove the users purchased products from the list of recommendations.
match (p:person { id: 294 })-[:transact]->(:order)-[:contain]->(prod:product) match (prod)<-[:contain]-(:order)-[:contain]->(rec_prod:product) where not (p)-[:transact]->(:order)-[:contain]->(rec_prod) return distinct rec_prod.id, rec_prod.nameThis statement shows us splitting up the work between multiple
matchdirectives. In the first we resolve theperson-labeled node with theidproperty set to294and return all theproduct-labeled nodes in said persons orders aliased byprod.In the second we take each
product-labled node (prodalias) and look for all “products of products” where that product is not in a transacted order by said person.Executed:
127.0.0.1:6379> graph.query prodrec "match (p:person { id: 294 })-[:transact]->(:order)-[:contain]->(prod:product) match (prod)<-[:contain]-(:order)-[:contain]->(rec_prod:product) where not (p)-[:transact]->(:order)-[:contain]->(rec_prod) return distinct rec_prod.id, rec_prod.name limit 1" 1) 1) "rec_prod.id" 2) "rec_prod.name" 2) 1) 1) (integer) 1 2) "Gorgeous Plastic Wallet" 3) 1) "Query internal execution time: 2.397600 milliseconds"This query is marginally more useful than the last but there’s a lot of room for improvement. One such improvement might be to sort and pick only the most popular products to return from the subset.
-
Returning the most popular 3 products as defined by inbound relationships to each product – this query builds on the former.
match (p:person { id: 294 })-[:transact]->(:order)-[:contain]->(prod:product) match (prod)<-[:contain]-(:order)-[:contain]->(rec_prod:product) where not (p)-[:transact]->(:order)-[:contain]->(rec_prod) return rec_prod.id, rec_prod.name order by indegree(prod) desc limit 3Here we layer in a crude attempt at finding the popularity of the product by using the node function that returns the number of inbound connections, or relationships, or edges for each product.
Executed:
127.0.0.1:6379> graph.query prodrec "match (p:person { id: 294 })-[:transact]->(:order)-[:contain]->(prod:product) match (prod)<-[:contain]-(:order)-[:contain]->(rec_prod:product) where not (p)-[:transact]->(:order)-[:contain]->(rec_prod) return rec_prod.id, rec_prod.name order by indegree(prod) desc limit 3" 1) 1) "rec_prod.id" 2) "rec_prod.name" 2) 1) 1) (integer) 33 2) "Mediocre Steel Gloves" 2) 1) (integer) 54 2) "Small Linen Wallet" 3) 1) (integer) 55 2) "Heavy Duty Silk Pants" 3) 1) "Query internal execution time: 132.870600 milliseconds"If the query is re-written to return the
product-labeled nodes themselves we can produce a graph in RedisInsight.match (p:person { id: 294 })-[:transact]->(:order)-[:contain]->(prod:product) match (prod)<-[:contain]-(:order)-[:contain]->(rec_prod:product) where not (p)-[:transact]->(:order)-[:contain]->(rec_prod) return rec_prod order by indegree(prod) desc limit 3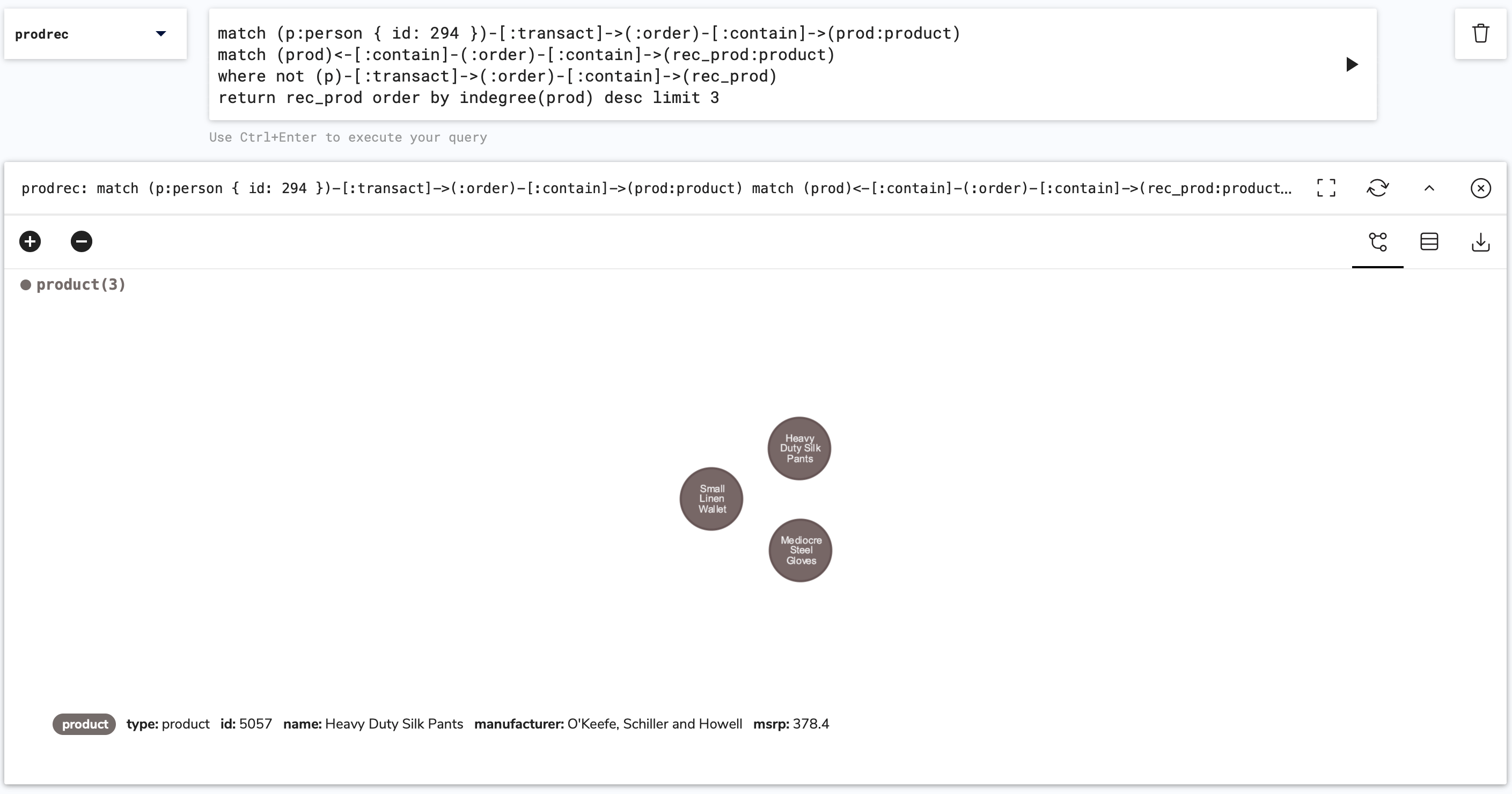
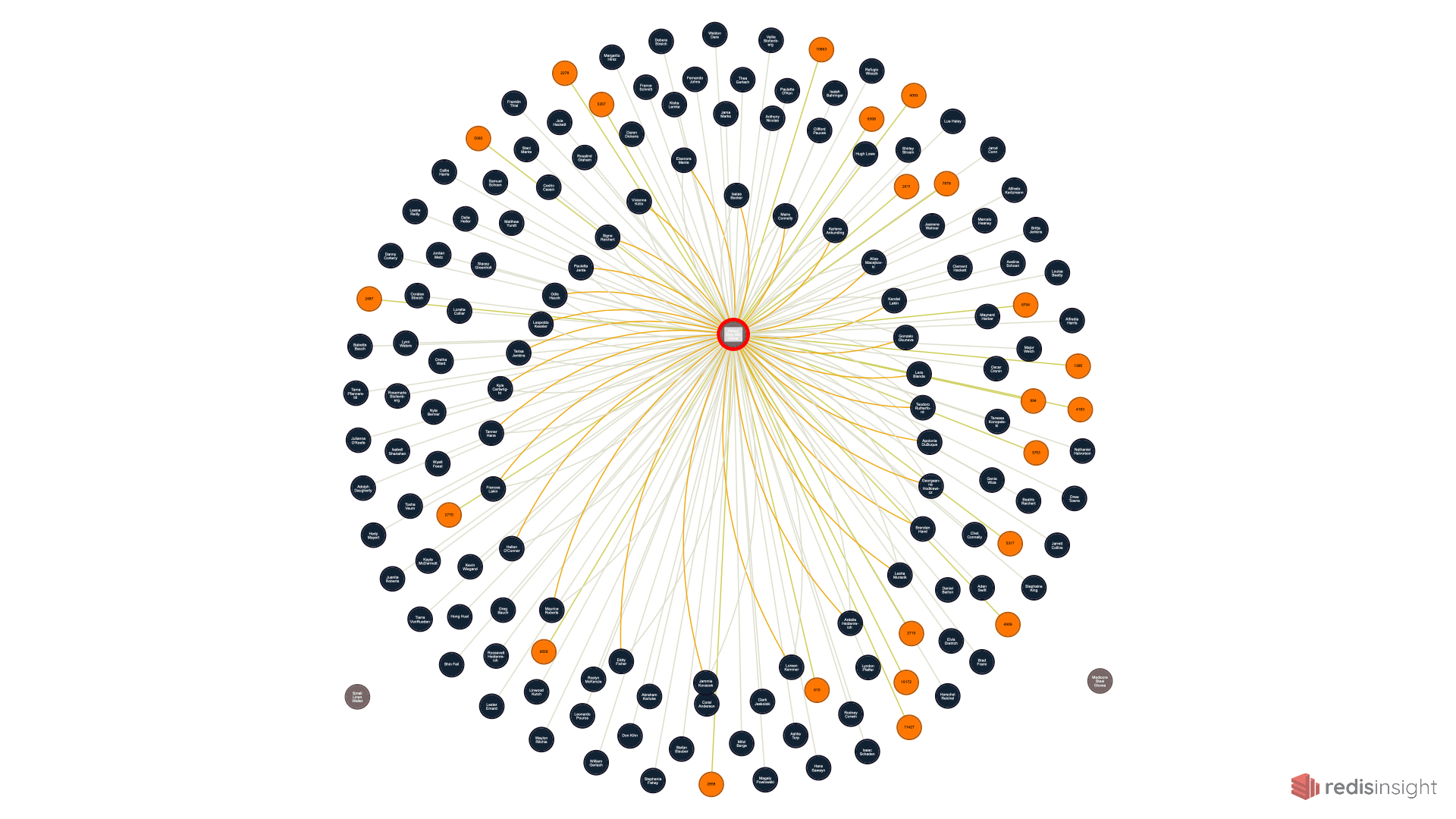
And selecting one of those products, like the “Heavy Duty Silk Pants”, shows an expansion of all that product’s connections. RedisInsight allows exports of graph views which is very, very slick.
Another optimization on this query might be to calculate, rank products recommended based on a rating that
peoplegiveproducts. Or, iterating on this solution and instead of getting the inbound connection count, get the count for each known edge type and weight them. It might also be useful to have abandoned cart or removal from cart events in place of add to cart events. As it is currently written, the graph generation tooling code generates a random set ofviewedges for products and from that a subset is created foraddtocartedges and from that another subset is created that are “contained” in an order. Tracking “negative” events, particular the two aforementioned ones, might be more useful than the existingaddtocartedge. -
The final example of recommendations is a query inspired by a work colleague of mine, Matthew Huckaby (on Twitter and GH). In this query we want to find the top 3 products (
idandname) viewed by people who have purchased queried product, id393.match (prod:product)<-[v:view]-(p:person)-[:transact]->(:order)-[:contain]->(:product { id: 393 }) return prod.id, prod.name, count(v) as count order by count desc limit 3In this query we specify a path to match against that points in both directions – which can be a bit mind blowing the first time you try an decipher… the cypher. Ha.
Let’s start in the “center” with our
person-labeled node with the aliasp. To the right we’re asking fortransact-typed edges pointing inbound toorder-labeled nodes. The order nodes should havecontain-typed edges pointing inbound to aproduct-labeled node. This node is the node we query against with theidproperty set to393. Note that only thepersonnode is aliased because everything else is just to query / filter for match against.To the left of the
personnode we have an inbound relationship requirement ofviewwith the aliasvinbound to aproductnode with the aliasprod.The return statement pulls the product
idandnameproperties in addition to the count ofvwhich gives usviewswithin the path match.From there things are smooth sailing with ordering and limits.
Executed:
127.0.0.1:6379> graph.query prodrec "match (prod:product)<-[v:view]-(p:person)-[:transact]->(:order)-[:contain]->(:product { id: 393 }) return prod.id, prod.name, count(v) order by count(v) desc limit 3" 1) 1) "prod.id" 2) "prod.name" 3) "count(v)" 2) 1) 1) (integer) 393 2) "Practical Wool Hat" 3) (integer) 35 2) 1) (integer) 17 2) "Small Marble Gloves" 3) (integer) 5 3) 1) (integer) 266 2) "Practical Cotton Shoes" 3) (integer) 5 3) 1) "Query internal execution time: 10.226500 milliseconds"
What’s next?
I hope you found this informative. Tinkering with Cypher/openCypher definitely requires clearing some mental hurdles in understanding. I find using a mix of technical docs with specific, broken down examples a great way of reinforcing learning.
The next few posts will be on the topics of performance and further optimizations to the query.
Additional Reading
The following documents are really useful for getting started with things. It is important to node that Redis Graph is implementing most but (yet) all of the openCypher commands and spec.
- the Cypher Query Language Reference (Version 9) from the OpenCypher resources
- the Cypher Style Guide also from the OpenCypher resources
- Redis Graph Commands for a full list of supported commands
- Redis Graph Cypher Coverage for notes on what commands aren’t covered (yet) by Redis Graph
- learn x in y minutes (cypher)
Cheers and Happy RedisConf day two!