Face identification with AWS Rekognition
Cloud AI/ML as a Service (AI/MLaaS) has been all the rage the last few years as we’ve seen major advancements and areas of expertise develop around services offered by Google, Amazon, and Microsoft. This commoditization of AI/ML-centric services has allowed businesses and integrators to take advantage of these services with very little investment. They allow users to:
- classify images
- extract subject(s) and topic(s) from bodies of text
- translate speech to text while identifying multiple parties
- track people in videos
…and more with just an account, credit card, basic know how and the will to do so. Gone are the days of training your own model (well, sort of) and futzing with OpenCV and TensorFlow (for example).
One controversial usage of this new AI/ML commodity is the realtime processing, classification, and identification of people. Amazon’s AWS Rekognition service places the issue front and center as law enforcement, governments, and private companies deploy its cheap offerings in their tools and workflows. Amazon has cited some positive use cases of the platform in a “classic don’t blame the tool” response. This post will follow suit, describing the process, ease, and function of use in private enterprise for fraud mitigation and prevention. First, though, here’s a bit about what sets Rekognition apart from the other AI/MLaaS offerings.
All three large cloud service providers offer vision or image-based AI/ML offerings allowing for image classification, text extraction (not exactly OCR), face detection and pair-wise face likeness scoring. Scoring faces pairwise is useful when a system has used external means to come up with candidate or potential matches in a system. Pairwise analysis is less useful, or even not useful at all, when the system doesn’t control searching/matching algorithm and needs to identify hits in a sea or collection of many faces. This is a particular strength of AWS’ Rekognition. At the time of development of the system outlined in this post, Rekognition was the only cloud service with this support. Since then Azure has launched a similar service, but Google still does not.
The Problem
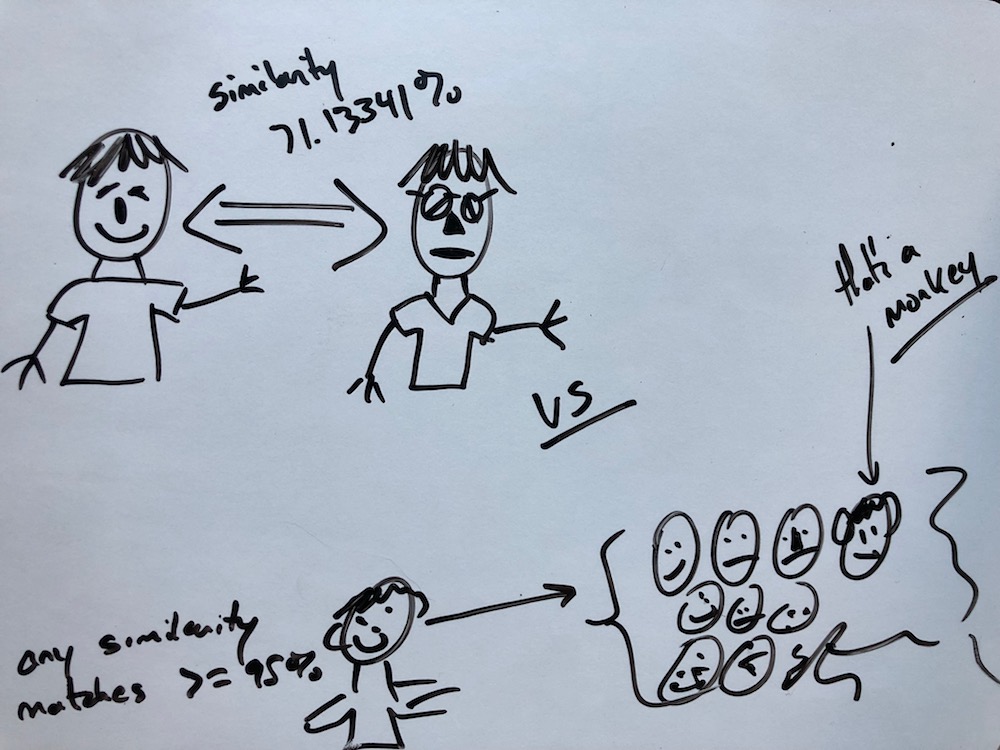
The problem to solve was to process, in near realtime, photos of people and cross identify those people in collections of … you guessed it, people. The existing collections would be composed of already known entities and would be used to ask Rekognition simple questions like “does the face in this image appear in this collection of 100k faces?”
Proof of Concept
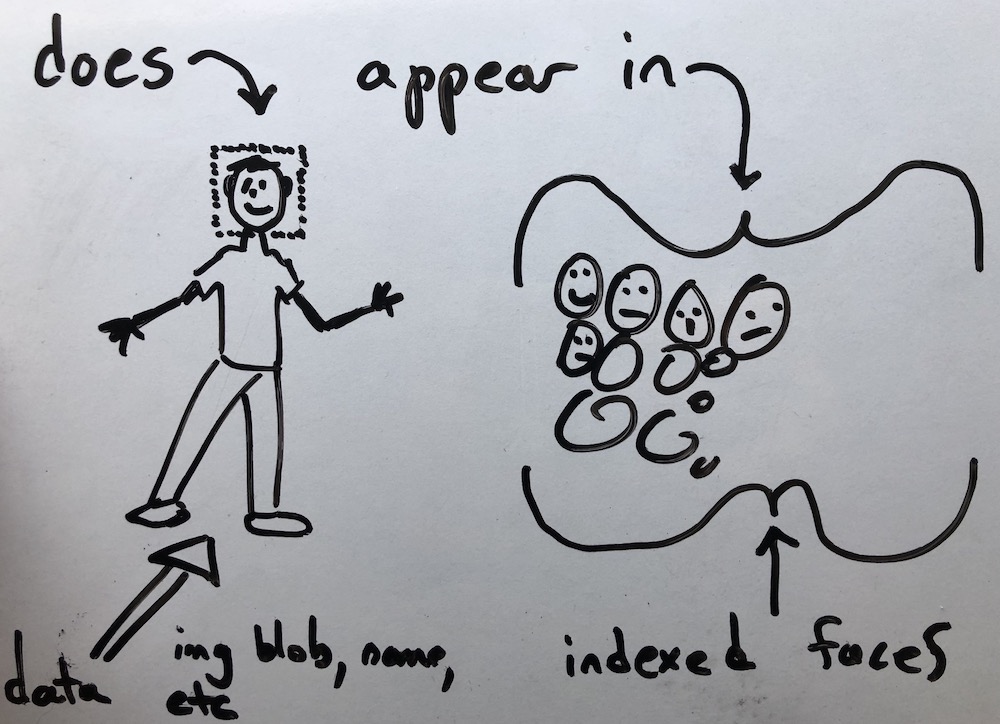
The first step towards a solution was to build a PoC aimed at testing the efficacy of the Rekognition service. To do this duplicate users with different photos were identified and pulled from existing systems. This gave established a reduced problem space for proving the value of Rekognition. After identifying the users, the users photos were collected and used to build a collection of faces. After construction of the collection, each face returned from the index operation was cross queried across the collection. The accuracy of the results from the PoC were shocking; the service was perfect at identifying human faces and nearly perfect at cross identifying the same people. In fact, there were a few cases where the team thought the service was wrong, but it turned out, after post-processing the image, the team came the same conclusion as Rekognition. With a few simple tests the team ruled that Rekognition was far superior to the custom, home-grown models previously attempted and that’s not even considering cross facial identification and scoring! So, how does Rekognition work?
Rekognition Basics
The gist of Rekognition for collections of faces is that images are indexed and then subsequently searched using either:
- a face UUID returned during the index operation (i.e. search the collection of faces with a face that’s already in the collection)
- an external image that is unindexed
…for hits based on similarity in the collection.
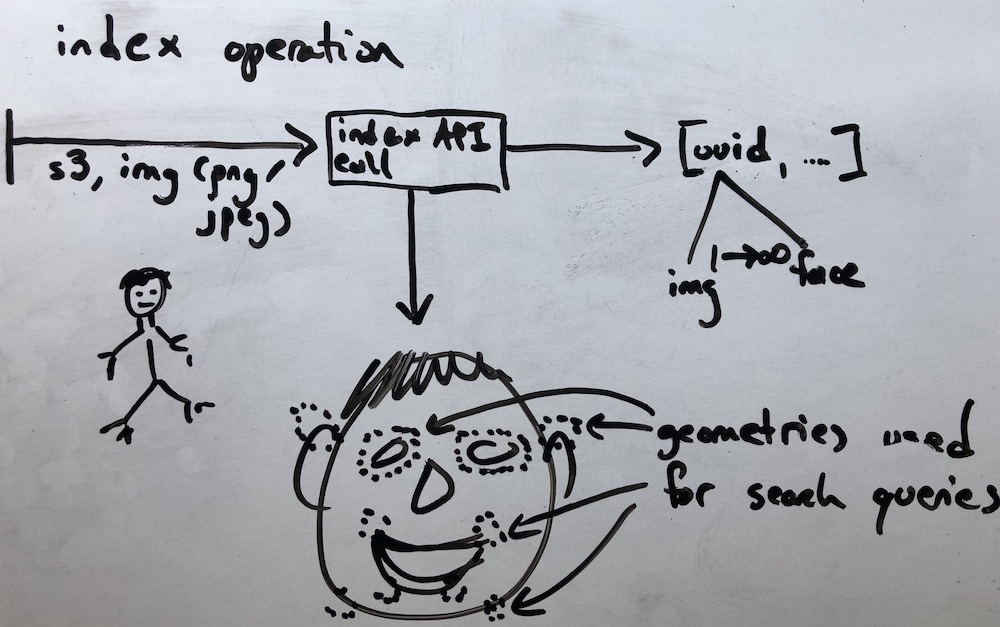
At a very high level the process looks like this:
- Create a face collection
- Index faces by either supplying the byte stream to the client or by supplying the path to the S3 bucket where the data pre-exists
- Receive and persist the index responses (containing a list of faces, dimensions, gender, emotions, etc…) joining the response data with business specific and relevant data (ex: customer id)
- Run through the faces derived from step #3, searching the collection for similar faces, specifying a minimum threshold similarity for a hit to be valid
- Analyze the resulting output, pointing out faces in the collection that look like other faces/images in the collection at the threshold defined in step #4
PoC Solution
A a simple Groovy script was created leveraging the following external dependencies:
- the AWS Java SDK
- Google Guava for collections and timing
- Apache Tika for MIME type analysis
#!/usr/bin/env groovy
@Grapes([
@Grab(group='org.apache.tika', module='tika-core', version='1.18'),
@Grab(group='com.amazonaws', module='aws-java-sdk-rekognition', version='1.11.408'),
@Grab(group='com.google.guava', module='guava', version='26.0-jre')
])
import com.amazonaws.auth.AWSCredentials
import com.amazonaws.auth.DefaultAWSCredentialsProviderChain
import com.amazonaws.auth.profile.ProfileCredentialsProvider
import com.amazonaws.regions.Regions
import com.amazonaws.services.rekognition.AmazonRekognition
import com.amazonaws.services.rekognition.AmazonRekognitionClientBuilder
import com.amazonaws.services.rekognition.model.IndexFacesRequest
import com.amazonaws.services.rekognition.model.CreateCollectionRequest
import com.amazonaws.services.rekognition.model.DeleteCollectionRequest
import com.amazonaws.services.rekognition.model.Face
import com.amazonaws.services.rekognition.model.FaceMatch
import com.amazonaws.services.rekognition.model.Image
import com.amazonaws.services.rekognition.model.ListCollectionsRequest
import com.amazonaws.services.rekognition.model.ListFacesRequest
import com.amazonaws.services.rekognition.model.SearchFacesRequest
import com.google.common.base.Stopwatch
import com.google.common.collect.HashMultimap
import java.io.FilenameFilter
import java.nio.ByteBuffer
import java.util.concurrent.TimeUnit
import java.util.List
import groovy.json.JsonOutput
import groovy.transform.Canonical
import org.apache.tika.Tika
def defaultCollectionId = 'ephemeral-faces-collection'
def defaultMatchConfidenceThreshold = 80F
def printErr = System.err.&println
def cli = new CliBuilder(header: 'AWS Rekognition Match Faces POC', usage:'./matchFaces [options] <directoryOfImagesWithFaces>', width: 140, footer: 'Note: The AWS Rekognition API only supports facial recognition for JPEG and PNG image formats. This script will select on those formats for index operations by Rekognition.')
cli.collectionId(args:1, argName:'id', "The collection id to use for this execution [${defaultCollectionId}]")
cli.delete('Delete the collection of faces post processing')
cli.forceRecreate('Force collection re-creation, if the collection exists')
cli.help('Show this menu')
cli.matchConfidenceThreshold(args:1, argName:'threshold', 'The match confidence threshold to use, values 0-100 [80]')
cli.saveImageData('Save image data as JSON for each response from AWS index image operation')
cli.verbose('Verbose output')
def cliOptions = cli.parse(args)
if (cliOptions.help || cliOptions.arguments().size() != 1) {
cli.usage()
System.exit(0)
}
def collectionId = cliOptions?.collectionId ?: defaultCollectionId
def matchConfidenceThreshold = cliOptions?.matchConfidenceThreshold ? Float.parseFloat(cliOptions.matchConfidenceThreshold) : defaultMatchConfidenceThreshold
def deleteCollection = cliOptions.delete
def forceRecreate = cliOptions.forceRecreate
def saveImageData = cliOptions.saveImageData
def verboseOutput = cliOptions.verbose
class ImageFilter implements FilenameFilter {
def acceptableImageTypes = ['image/jpeg', 'image/png']
def tika = new Tika()
public boolean accept(File file, String filename) {
acceptableImageTypes.contains(tika.detect(file))
}
}
def sourceImages = new File(cliOptions.arguments().first())
if (matchConfidenceThreshold < 0 || matchConfidenceThreshold > 100) {
printErr "The supplied matchConfidenceThreshold of ${matchConfidenceThreshold} is invalid. Please supply a value between 0-100 or remove the argument to use the default value of 80."
System.exit(-1)
}
if (!sourceImages.exists()) {
printErr "The directory '${sourceImages.path}' does not exist."
System.exit(-1)
}
def listOfImages = sourceImages.listFiles(new ImageFilter())
if (!listOfImages) {
printErr "There are no images suitable for processing in the directory '${sourceImages.path}'"
System.exit(0)
}
def awsRekognitionClient = AmazonRekognitionClientBuilder
.standard()
.withRegion(Regions.US_WEST_2)
.withCredentials(new DefaultAWSCredentialsProviderChain())
.build()
def collectionExists = awsRekognitionClient.listCollections(new ListCollectionsRequest()).collectionIds.contains(collectionId)
if (collectionExists && forceRecreate) {
awsRekognitionClient.deleteCollection(new DeleteCollectionRequest().withCollectionId(collectionId))
awsRekognitionClient.createCollection(new CreateCollectionRequest().withCollectionId(collectionId))
} else if (!collectionExists) {
awsRekognitionClient.createCollection(new CreateCollectionRequest().withCollectionId(collectionId))
}
def existingFaces = awsRekognitionClient.listFaces(new ListFacesRequest().withCollectionId(collectionId)).faces
def existingFacesExternalImageIds = existingFaces.collect { face ->
face.externalImageId
}
def totalProcessingStopwatch = Stopwatch.createStarted()
def perImageProcessingStopwatch = Stopwatch.createUnstarted()
listOfImages.each { file ->
if (existingFacesExternalImageIds.contains(file.name)) {
if (verboseOutput) {
println "The image file ${file.name} has already been indexed. Skipping."
}
} else {
perImageProcessingStopwatch.start()
def indexFacesRequest = new IndexFacesRequest()
.withImage(new Image()
.withBytes(ByteBuffer.wrap(file.getBytes())))
.withCollectionId(collectionId)
.withExternalImageId(file.name)
.withDetectionAttributes('ALL')
def indexFacesResponse = awsRekognitionClient.indexFaces(indexFacesRequest)
perImageProcessingStopwatch.stop()
if (verboseOutput) {
println "Found ${indexFacesResponse.faceRecords.size()} faces in image ${file.name} in ${perImageProcessingStopwatch.elapsed(TimeUnit.MILLISECONDS)} ms"
} else if (indexFacesResponse.faceRecords.size() != 1) {
println "Found ${indexFacesResponse.faceRecords.size()} faces in image ${file.name} in ${perImageProcessingStopwatch.elapsed(TimeUnit.MILLISECONDS)} ms"
}
if (saveImageData) {
new File("${sourceImages.path}/${file.name}_results.json").write(JsonOutput.prettyPrint(JsonOutput.toJson(indexFacesResponse)))
}
perImageProcessingStopwatch.reset()
}
}
totalProcessingStopwatch.stop()
if (verboseOutput) {
println "Took a total of ${totalProcessingStopwatch.elapsed(TimeUnit.SECONDS)} seconds to index ${listOfImages.size()} images"
}
println "/----------------------------------------------------------------------------------------------------------------------------------------\\"
println "| Source Face ID | Source File | Target Face ID | Target File | Similarity |"
println "|----------------------------------------------------------------------------------------------------------------------------------------|"
def leftAlignedFormatOutput = "| %s | %-20s | %s | %-20s | %-10f |%n"
existingFaces.each { face ->
awsRekognitionClient
.searchFaces(new SearchFacesRequest()
.withCollectionId(collectionId)
.withFaceId(face.faceId)
.withFaceMatchThreshold(matchConfidenceThreshold))
.faceMatches.each { faceMatch ->
System.out.format(leftAlignedFormatOutput, face.faceId, face.externalImageId, faceMatch.face.faceId, faceMatch.face.externalImageId, faceMatch.similarity)
}
}
println "\\----------------------------------------------------------------------------------------------------------------------------------------/"
if (deleteCollection) {
awsRekognitionClient.deleteCollection(new DeleteCollectionRequest().withCollectionId(collectionId))
}
From there, the script creates a Rekognition collection (if one doesn’t already exist [unless it’s overriden]), uses Tika to evaluate and find JPEG/PNG images (those only supported by Rekognition), indexes the images, then cross queries the collection writing the results to a table. The script additionally supports data output and recreate/delete collection operations.
➜ rekognition-scripts git:(master) ✗ ./matchFaces
usage: ./matchFaces [options] <directoryOfImagesWithFaces>
AWS Rekognition Match Faces POC
-collectionId <id> The collection id to use for this execution [ephemeral-faces-collection]
-delete Delete the collection of faces post processing
-forceRecreate Force collection re-creation, if the collection exists
-help Show this menu
-matchConfidenceThreshold <threshold> The match confidence threshold to use, values 0-100 [95]
-saveImageData Save image data as JSON for each response from AWS index image operation
-verbose Verbose output
Note: The AWS Rekognition API only supports facial recognition for JPEG and PNG image formats. This script will select on those formats for
index operations by Rekognition.
The following is an example collage with two sets of images; a1,a2 and b1,b2.

➜ rekognition-scripts git:(master) ✗ ./matchFaces -matchConfidenceThreshold 50 test_images
Found 2 faces in image a1.jpg in 2010 ms
Found 2 faces in image a2.jpg in 2823 ms
Found 4 faces in image b2.jpg in 1558 ms
Found 3 faces in image b1.jpg in 2556 ms
/----------------------------------------------------------------------------------------------------------------------------------------\
| Source Face ID | Source File | Target Face ID | Target File | Similarity |
|----------------------------------------------------------------------------------------------------------------------------------------|
| 470f1a1e-72ce-49b7-8d92-db0676f232ac | a1.jpg | eb33efc2-83d4-439b-a1e2-09ebfebffaa5 | a2.jpg | 74.834282 |
| 7704c206-f754-4d23-9032-675be7b2cf37 | b2.jpg | c16baede-2247-4fc9-83da-572b2b1050ab | b1.jpg | 73.889526 |
| c16baede-2247-4fc9-83da-572b2b1050ab | b1.jpg | 7704c206-f754-4d23-9032-675be7b2cf37 | b2.jpg | 73.889603 |
| eb33efc2-83d4-439b-a1e2-09ebfebffaa5 | a2.jpg | 470f1a1e-72ce-49b7-8d92-db0676f232ac | a1.jpg | 74.834274 |
\----------------------------------------------------------------------------------------------------------------------------------------/
The script outputs the number of detected faces in each submitted file and constructs a table linking the search face UUID to the match face UUID also citing the file name and the similarity score. In this case, the minimum confidence was set to %50 and Rekognition returned hits in the low seventies.
Initial, trial solution
The next step in the development process was to gather data on the performance of Rekognition against an non-curated, raw stream of data input. For this a scheduled job ran daily on the previous days worth of images both indexing and reporting. The scripts leveraged several SQL and no-SQL data stores to gather the relevant data needed for the query operations and then went about their respective tasks. The results of the trial solution were written to Google Sheets for human verification and, in an effort to keep the results to a reasonable size, implemented some basic heuristics:
- consider only the largest face from images containing multiple faces – in cases where this occurs, the largest face is considered to be the closets to the camera and given the instruction in the app is to take a selfie, that individual is the one to scrutinize
- exclude excessive entries from pre-determined bands of 5 percent blocks, i.e. for entries
= %90 and <= %95, retain the top {x} entries
The trial solution was set to process about a year back in time and began indexing forward one day at a time. The catch up period happened in bulk, but marginal operations occurred daily once complete. The aforementioned resulting Google Sheets contained results data and supplementary data to aid in the confirmation of the Rekognition hit. The team spent a few minutes every day to review and confirm or reject the matches.
The trial solution ran for a number of weeks which provided the time necessary to learn from the data. This allow the team to better inform the final solution, business impact, and resulting system integrations including some of the following specific questions:
- In cases where multiple faces are returned from a single image, which face is used? Keep the current strategy of the largest only, report on all of them, or select a certain face based on position or size?
- What is a reasonable threshold to set for a minimum similarity when querying against the collection?
- How to handle scenarios with highly confident false positives?
- Cost reduction in dealing with such a large corpus of data.
- Intelligent collection splitting in cases where the number faces exceeds the limits imposed by AWS.
- How to best handle repeat queries and forward scanning limitations; disjoint indexing and searching on new collections?
Final Solution
The final solution was dramatically different from the PoC and trial solutions in that it responded to data streams in real time. The service bound to several up and newly downstream Kafka topics, consuming and generating messages. The service also locally persisted all data, indexing specific fields considered most relevant to the downstream systems, and exposed REST endpoints for consumption by other non-streaming-based systems.

The results from the trial solution confirmed heuristic of dropping all but the largest face in addition to reporting that only 1/100 of a percent of images had multiple detected faces. The results also helped us inform our cutoff for automated confirmation; a cutoff set at %98.5 similarity. Generally speaking most true hits are within a point of %100. The service weighted accuracy of downstream hits or events over absolute matching and thus were happy to make the trade off of potential missed hits for more accurate ones.
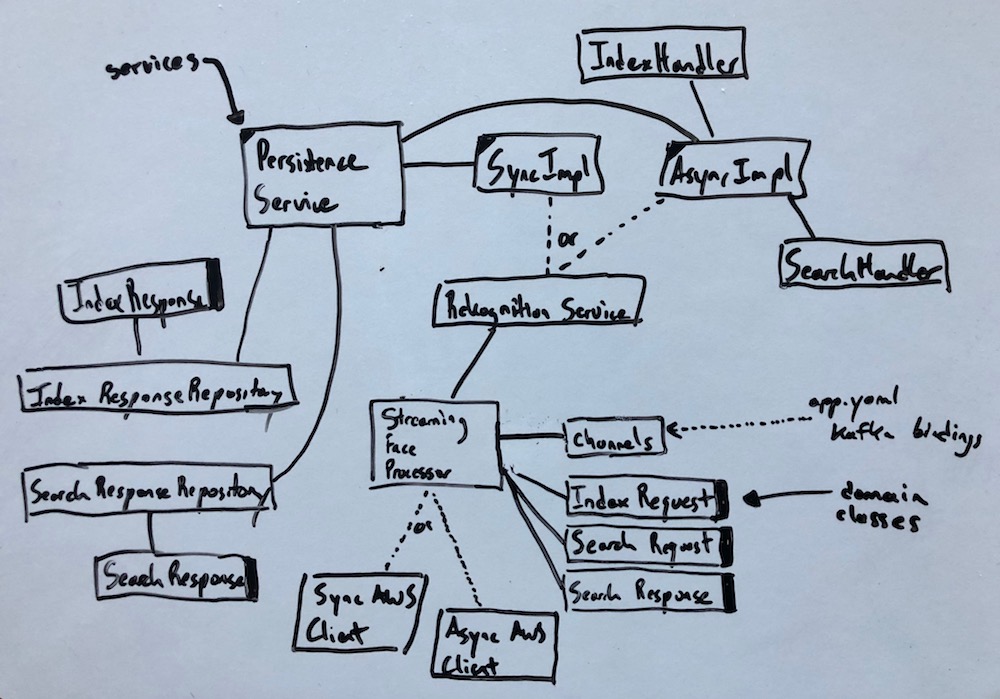
The stream processing app is a SpringBoot application, which leverages score spring in addition to:
- spring actuator
- spring data
- spring boot web
- spring cache with caffeine
- spring cloud stream (including kafka support)
An application.yaml defines the stream input and output bindings which are additional declared in a MessageChannels interface.
Indexing overview
As images are uploaded and stored in S3, corresponding messages are generated and dropped in long-lived TTL Kafka topics that a Rekognition Service implementation listens to via Spring’s StreamListener annotation. There are two service implementations; a sync one and an async one. The async service allows the processor to scale past the partition count for the topic with an increased risk of data loss in the event of failure (even with manual dead letter queue functionality). The scaling potential allows the service to make great gains in bulk, catch up processing against Rekognition. This is especially useful when the collection grows to a certain scale and all Rekognition API operations against the collection take more than a second. The result of these operations are broken into their key, indexed attributes and stored alongside the entire JSON index response payload. Duplicate entries are not re-processed and images that contain no faces aren’t stored. The largest face from a successful index operation is dropped in an intra-service Kafka topic for searching.
Searching overview
The same services that allow for sync or async indexing also allow for searching. Just like index operations, search results are persisted only if hits are returned above the configured threshold of %98.5 similarity. This response payload is persisted and a message is created and dropped into a final Kafka topic for consumption by downstream systems.
Solution Optimizations
Most of the optimizations around Rekognition are meant to address the cost of making API calls against the service, particularly with large data sets.
- Pre-process images to detect any face prior to calling Rekognition – Rekognition bills for all calls, including index operations where no faces are detected – i.e. a photo of fruit in a bowl or a puppy in a field. Rekognition’s real value-add in this case is cross identifying faces in collections. Other libraries like OpenIMAJ and OpenCV could be used as gatekeepers to such a system, only allowing for images with detected faces to flow through. See Facial recognition using OpenCV in Java and this post on using OpenIMAJ.
- Deploy a persistent, probabilistic data structure like a Bloom Filter to keep track of processed but invalid data – In an environment where Kafka topic TTLs are indefinite and topic data is considered the source of truth, watch for re-played messages. To guard against un-necessary re-processing of images that didn’t return faces in the first index operation pass, deploy a persistent BloomFilter (see Redisson’s distributed objects) to keep track of which messages your services have already seen.
- Consider routing requests to different collections in cases where data isolation garantee can be met
Finally, in an effort to reduce false positives produced by the service, consider using a graph to store the similarities between search hits. Combine this data with the metadata derived by face in its index response to query with similarity data and classifier responses. This would theoretically provide better hit accuracy than Rekognition natively. Consider the following scenario:
- An image is indexed; revealing a single face, a face classified as %96 male.
- A second image is indexed; revealing a single face, a face classified as %100 female.
- Both faces are in a collection and the collection is searched using the first face, the male, in which Rekognition responds stating the only other face is a hit at %97.99 similarity.
I plan on updating the service mentioned in this post to include the optimizations in the coming weeks as I need it for a side project. Look for it!
-Josh